
The setting
Continual learning, in the form I care about here, is the problem of training a single model on a sequence of task families that arrive one after the other. A new domain appears, or a new difficulty level, and the model is asked to become competent at it without losing what it already knew. The failure mode is old and familiar: fine-tune on the second family, and the first family quietly degrades.
Most of the common remedies come with an external cost. A teacher model needs to exist somewhere, a set of golden demonstrations needs to be written by someone, or a reward model needs to be trained and then kept honest. Each of these is reasonable in isolation, but they accumulate into a fairly heavy surface area.
VRD starts from a narrower assumption. It asks whether you have, for the domain of interest, a programmatic verifier: a function that can look at a task and a candidate solution and return a judgement. Verifiable domains are more common than they may appear. Arithmetic is verifiable. Code with unit tests is verifiable. A great many structured science questions, when phrased as multiple choice or as short exact-match answers, are verifiable. Where such a verifier exists, it can play the role of teacher, critic, and reward model at once, and it is cheap and tamper resistant in a way that none of the other three entirely are.
What the recipe does
Within each stage, training proceeds in a small number of cycles. The model samples a handful of candidate solutions for each task, drawing from its own current policy. The verifier looks at each candidate and produces a scalar reward, which the recipe turns into a per-trace weight through a softmax at a chosen temperature. The weighted traces are then folded back into the model via a single cross-entropy loss on a LoRA adapter. At the end of the cycle, a refreshed sampler is created from the updated weights, and the next cycle begins from there.
Around this core loop sit two small mechanisms that do most of the work in keeping training stable across a long sequence of stages.
The first is a replay buffer. Every verified trace is kept, and at every subsequent cycle, some fraction of the batch is drawn from the pool of traces produced in previous cycles and previous stages. When the model trains on the second stage, the first stage is still gently present in every batch; when it trains on the third, the first two are present as well. The replay multiplier controls how loud this background voice is, but the essential idea is that the model is never asked to learn the new thing in the absence of the old things.
The second mechanism is a failure-driven curriculum. Between cycles, the recipe looks at the per-task pass rates from the most recent round of sampling. Tasks that were solved easily have their search budget reduced; tasks that were failed have theirs increased. The total budget across tasks is held approximately constant, so compute flows from the parts of the distribution that are already covered to the parts that still need attention. Tasks the model has never seen are treated as maximally difficult.
Between stages, the LoRA weights and the optimizer state are carried forward without any reset. The checkpoint from stage N becomes the initialization for stage N plus one, which means that the second stage begins in a place that has already been shaped by the first, and not in a place that has been scrubbed back to the base model.
The result on SciKnowEval
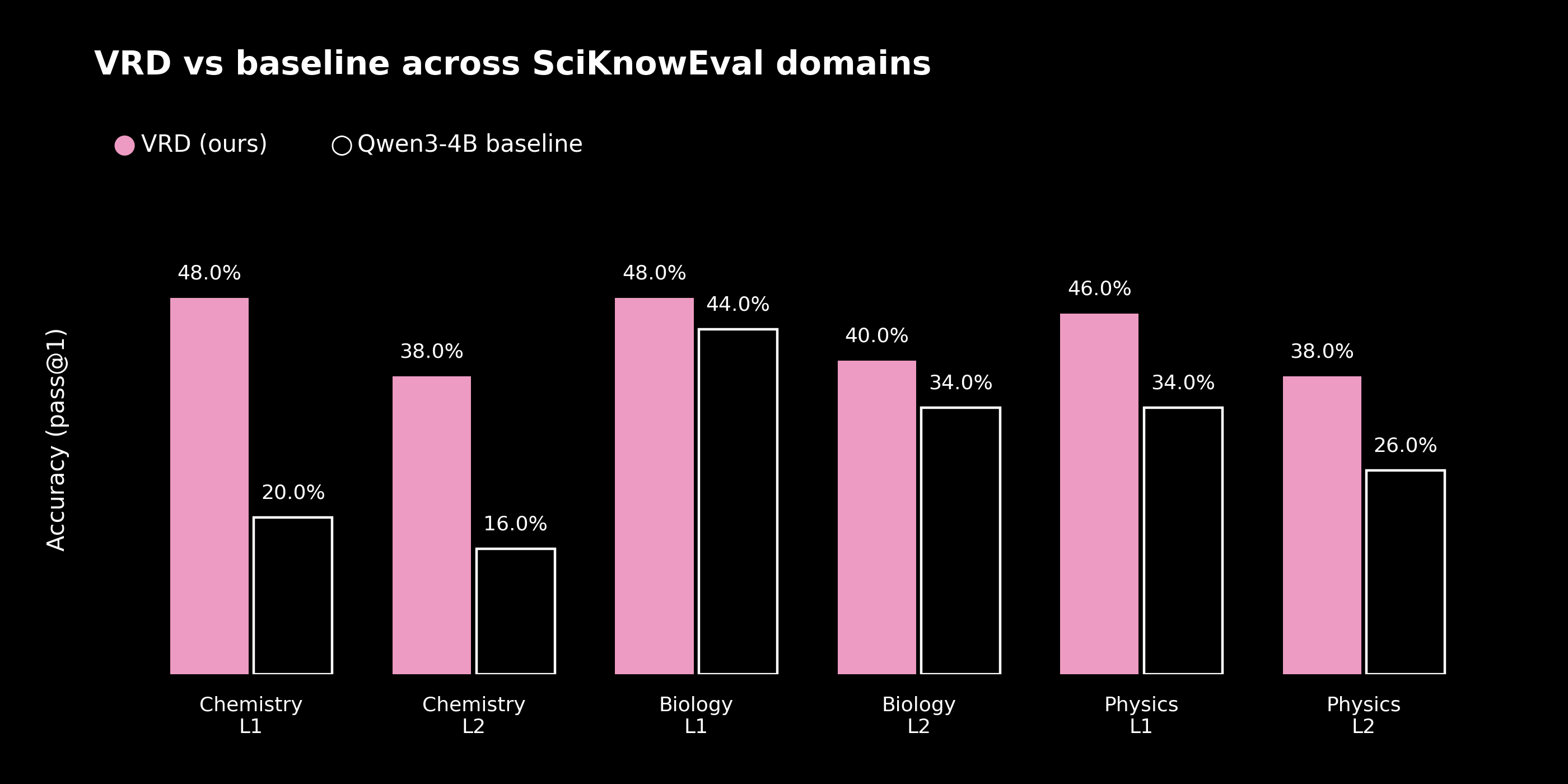
To evaluate the recipe in a concrete setting, I ran it on SciKnowEval, a science multiple-choice benchmark covering Chemistry, Biology, and Physics at two difficulty levels. The level one questions are closer to knowledge recall, and the level two questions are closer to application. In total the benchmark comprises 9,195 tasks. The base model is Qwen/Qwen3-4B-Instruct-2507, trained with a LoRA adapter of rank 32, three cycles per stage, four base candidates per task, batch size 16, a 512 token generation limit, and a learning rate of 2e-4.
The three domains were presented as a sequence of three stages, with both difficulty levels in each. Chemistry first, then Biology, then Physics. After every stage, the model was evaluated on every domain it had already seen.
| Domain | Level | Baseline | VRD | Improvement |
|---|---|---|---|---|
| Chemistry | L1 (recall) | 20.0% | 48.0% | +28.0pp |
| Chemistry | L2 (application) | 16.0% | 38.0% | +22.0pp |
| Biology | L1 | 44.0% | 48.0% | +4.0pp |
| Biology | L2 | 34.0% | 40.0% | +6.0pp |
| Physics | L1 | 34.0% | 46.0% | +12.0pp |
| Physics | L2 | 26.0% | 38.0% | +12.0pp |
The largest gains appear where the baseline is weakest. Chemistry at level one rises from 20.0% to 48.0%, a factor of roughly 2.4. Biology, which starts from the strongest baseline, improves least. This is the shape one would expect from a recipe whose curriculum is organized around failure.

Retention across stages
The harder question in any continual learning experiment is what happens to the earlier domains as the later ones are being trained. This is where the replay buffer earns its keep.

Chemistry, after two further stages of training on Biology and Physics, retains 44.0% at level one and 34.0% at level two. Biology, after one further stage, retains 46.0% at level one and 38.0% at level two. The cost of each additional stage is, averaged across domains and levels, on the order of two percentage points. It is not free, but it is gentle and regular enough to plan around. When Chemistry is revisited at the end of training, its level one accuracy is still more than twice its pre-training baseline.
Training dynamics
The plot below compares the mean verifier reward of the base model against the mean reward at the end of all three stages, across the six domain-level pairs.

The graded verifier used in these experiments assigns a reward of 1.0 to a correct answer, 0.3 to a response that contained a well-formed but wrong answer, and 0.0 to a response where no answer could be extracted at all. The improvement in mean reward therefore reflects two separate gains: the model is solving more tasks correctly, and extraction failures become rare even when the final answer is wrong.
Design choices
There is no policy gradient term in the loss. There is no KL penalty against a frozen reference. There is no soft target from a teacher distribution. The loss is cross-entropy on hard targets, with the rewards entering only through the relative weighting of candidates within each task. With fewer terms in play, it is easier to reason about why a given update has moved the model in a given direction, and easier to diagnose the recipe when it misbehaves.
The recipe is also strictly on policy. The only traces the model ever trains on are traces it produced itself and that the verifier then ratified. There is no separate collection phase, no off-policy correction to worry about, and no drift between the data distribution and the current policy beyond what accumulates within a single cycle before the sampler is refreshed. This keeps the pipeline honest about what the model can actually do at each moment.
Finally, the verifier is the contract. Substituting a new verifier for a new domain is the main extension point, and the rest of the recipe is designed to sit quietly around it. A code verifier, a trajectory-level tool-use checker, a theorem proof checker: each of these would slot into the same outer loop without asking the recipe to be rewritten.